Understanding Domain-Driven Design (Part 3)

Introduction
Hello there! We’re back with our “Understanding Domain-Driven Design” series. So far, we’ve talked about Domain, Bounded Context, Use Case, file structure, and testing, in Parts 1 & 2. I would suggest you read those first if you haven’t done it, yet.
In this part, we will go through abstracting smaller parts. We will also talk about avoiding unnecessary complexity.
The Big Picture
The Use Cases are essentially a set of instructions to our system. They’re the big picture. That’s why, most of the time, testing a use case’s behavior already reveals underlying problems without delving deeper. But, there are some cases where the big picture is not the full picture. Sometimes, we need a little more detail. Let’s think about the “buying a flight ticket” process from the previous part.
Abstracting Use Cases Into Smaller Building Blocks
In traditional apps, you might find all use cases handled by a single controller, such as BookingController. This controller would manage the entire process of buying a flight ticket. Checking availability, calculating prices, making reservations, processing payments, generating tickets, sending notifications, and the list continues. When the complexity of this controller becomes hard to manage, we look for ways to split it into smaller units.
Ultimately, we should anticipate and address those potential problems before they become problems, even in DDD apps. We have to be careful, though: we don’t want to overcomplicate our solutions while trying to simplify them. This distinction is not an easy challenge. It is hard. You need experience to do that properly. I will give you a little secret, though. When you focus on the behavior of the system rather than implementation details, it gets easier. What does that mean? And how do we focus on the behavior? We create a test case explaining the desired behavior. I explained this briefly in the previous article. We can leverage Test-Driven Development (TDD) to design our system rather than testing its implementation.
Testing The Behavior
Imagine, you have a Symfony console command that converts CSV file into database entries.
#[AsCommand(name: 'app:booking-importer:store-csv-file')]
final class StoreCsvFileCommand extends Command
{
// ...
protected function execute(InputInterface $input, OutputInterface $output): int
{
$entry = $this->csvToDbConverter->convert($input->getArgument('csvPath'));
$this->bookingRepository->save($entry);
$output->writeln('CSV content successfully converted!');
return Command::SUCCESS;
}
}
Let’s create an integration test case following the framework documentation. Typically, if you don’t understand the behavior’s importance, the test becomes an implementation test.
public function test_execute(): void ❌ (A)
{
$applicationContainer = // ...;
$command = $applicationContainer->get(StoreCsvFileCommand::class);
$commandTester = new CommandTester($command);
$commandTester->execute(['csvPath' => 'someFile.csv']);
// A private assertion method to validate command name
self::assertLastExecutedCommandName('app:importer:store-csv-file'); ❌ (B)
$actualOutput = $commandTester->getDisplay();
$expectedOutput = 'CSV content successfully converted!';
self::assertSame($expectedOutput, $actualOutput); ❌ (C)
}
Let’s review this test case together. I’ve already marked some problems with the ❌:
A: The name doesn’t provide any information about the use case and its behavior.
B: We are already retrieving the command by its class name. We don’t care about its configuration name. The configuration name doesn’t validate anything about the command’s behavior.
C: The output text of the command is irrelevant when it comes to its behavior. The behavior is to store CSV entries in the database, not to output a particular text. How would I change this test case?
public function test_it_converts_csv_file_into_database_entries(): void ✅ (A)
{
$applicationContainer = // ...;
$command = $applicationContainer->get(StoreCsvFileCommand::class);
$commandTester = new CommandTester($command);
$commandTester->execute(['csvPath' => 'someFile.csv']);
$expectedEntries = [...]; // Array of expected entries
$actualEntries = $applicationContainer->get(ImportedBookingRepository::class)->findAll();
self::assertEquals($expectedEntries, $actualEntries); ✅ (C)
}
A: We described the behavior of the use case in the test case name.
B: The command name is not that important. It doesn’t impact the behavior; it’s a configuration detail. Once you validate this command’s behavior, you already know you’re testing the correct command, implicitly confirming the command name.
C: We asserted against the expected outcome, not the command output. Once again, we can change this output message at any time. It won’t affect the use case itself. The test case also plays a role in documenting the use case behavior. To better understand the use case, we can break it down into steps:
We need a command
That will take a CSV file path
When we run this command, there will be corresponding database entries, generated from the CSV file.
This is a simple example, but you can already see the big picture from it. It’s much easier to think about smaller abstractions when you have that. Test-Driven Development (TDD) helps us see the big picture.
Why Do We Even Need Smaller Abstractions?
The short answer is you don’t always need them. Sometimes, a simple use case is more than enough. Then, there are other times when your use case gets complicated and harder to maintain. It starts to hold different types of behaviors. It gets complicated. That’s usually the signal to start abstracting it into smaller units. There is no clear line between both decisions. You, as a software architect, need to draw that line between them. Running a business is never easy, and neither is the process of abstracting its problems. We need to find ways to decompose those complex problems into smaller, simpler ones. This approach helps us in validating the behavior of each small solution individually.

Strategic Abstraction
If your use case is simple enough, such as our creating post example, you don’t have to extract it into a service. There is no real benefit to communicating through that service. This separation adds an unnecessary layer of complexity. You’re creating unnecessary dependencies. Dependencies aren’t just about third-party libraries; you also need to manage dependencies between components. It only makes sense to abstract your problem away if it’s complex enough. If you are unable to solve it, then try abstracting it into smaller problems.
If you remember the “real-world” example of CreatePost from the previous article, we abstracted the part that converts Markdown to HTML there. It’s already a big problem, not necessarily what we need to solve in the CreatePost use case. Now, our use case depends on that abstraction. Additionally, there is one abstraction that is almost a de facto industry standard for all Domain-Driven Design projects—it’s called “Repository”. I’m pretty sure you know about it. Have you ever asked yourself why we abstract this part of our applications, almost in all projects? The answer is simple: because we benefit from it. They encapsulate data access logic and help us focus on the domain rules and behavior. They protect the domain model from knowing the details of how we store or retrieve data. When we abstract this layer of details, it becomes really easy to test our use cases. We replace that repository abstraction with an InMemory implementation. So we don’t need to run a whole datastore infrastructure to validate our use cases. That abstraction solves a complex problem for us. In this case, the trade-off we’re taking for abstracting that layer is paying us off. That’s what you should always focus on.
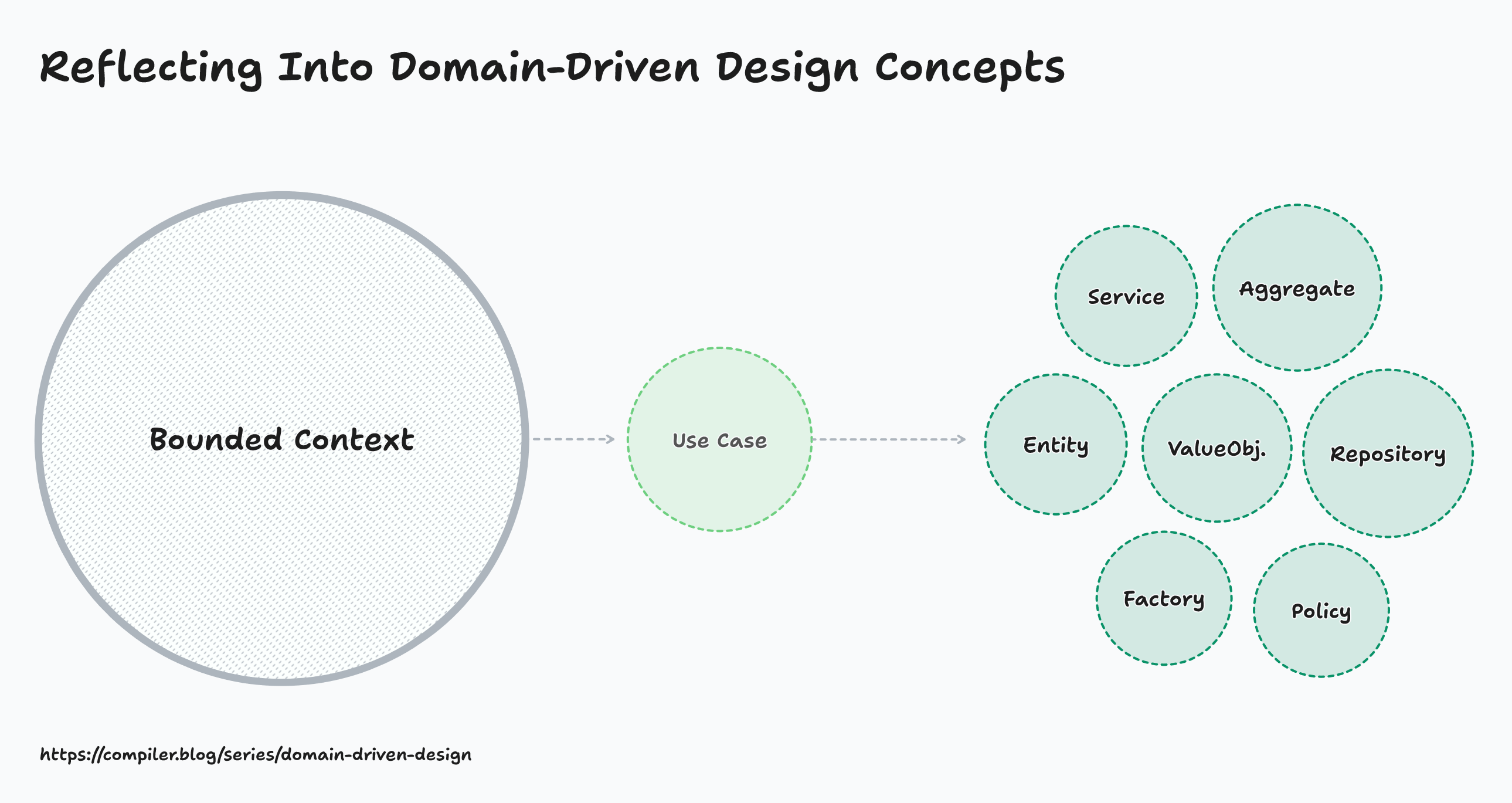
Conclusion
In the reference image above, there are several domain concepts, such as Service, Entity, ValueObject, Factory, and more. I won’t go into detail on each of them, as there are many learning resources available online. I want to help you understand the idea behind Domain-Driven Design (DDD) and those abstractions, rather than simply teaching individual technical concepts.
As we come to the end of this series, I hope you have learned something valuable from it! Feel free to share your thoughts in the comments! I will continue to work on examples for the Blogging Platform and share them as an open-source project on my GitHub profile. I will publish articles on software-related topics every week.
If you enjoyed this article series and don’t want to miss the next one, let’s connect on https://twitter.com/akmandev and https://www.linkedin.com/in/ozanakman for more content like this!



